

Siloed Data Leads to Blind Spots For Ingredients in the Headlines
The headlines are frequently filled with the latest product that has an ingredient that either has an impact on human or animal health or causes environmental damage. The result: millions or billions of dollars in loses. While it’s not revelatory to recognize the importance of staying on top of potentially harmful ingredients in consumer goods formulas, it proves a challenge for many companies.
This is especially true as technological advances have changed the way information flows between academic sources, regulatory agencies, news media and consumers. There are countless examples of lawsuits and public relations fall outs from harm or the potential of harm to consumers that prove manufacturers must remain vigilant against destructive ingredients. Whether these lawsuits come to fruition or not, they do lasting damage to a company’s reputation and bottom line. Even potentially risky ingredients that cause consumer uproar must be on manufacturers’ radar to outpace a problem.
One of the concerns for companies is the sheer amount of online data, growing exponentially each day, and residing in far-flung corners of the Internet. An ingredient such as Titanium Dioxide , used in hundreds of food products, was once believed to be innocuous. As more data emerges of its potential harm or as more conversation surrounding it brings the risk of misinterpretation by consumers, companies must make the decision to reformulate – or risk lawsuits, loss of consumer trust, and billions of dollars in market value.
While most established manufacturers have a handle on the present state of their categories, waiting until the FDA bans an ingredient means waiting too long. Even waiting until an ingredient’s potential risk splashes across headlines is waiting too long. There are three concerns for manufacturers right now:
- An overabundance of data across diverse data sets including scientific, regulatory, market and consumer, billions of datapoints where a new concern about an ingredient linked to a health effect or environmental damage could linger and be a spark for social spread.
- Missing key inputs or bifurcated data monitoring, with commercial teams (e.g. social media and market data) and non-commercial teams (e.g. regulatory and scientific data) examining different data sets.
- Not understanding how these distinct data sources interact and the patterns of Spark and Spread of data of concern.
An overabundance of data across diverse data sets. The internet has made way for rich data sets that grant manufactures the ability to understand the consumer, as well as see emerging scientific thought and regulatory action. This can be both a blessing and a curse; the enormity of existing (and ever-growing) data and its diverse inputs can quickly become overwhelming to manage, analyze and make sense out of – this can lead to information overload and inefficiencies.
One beneficial output of the vast amount of data available is the ability to more easily monitor ingredients. To do so with any exacting result, means a manufacturer must first digest the totality of the data that exists from a particular set of inputs, filter these documents down to only data points that mention a specific ingredient and a set of concerns such as disease states, and further clarify to a set of flagged documents or data points that are relevant to understanding the ingredient’s potential harm or lack of.
An example, Methyl Paraben: From the year 2000 through 2020, there were 4000 + documents mentioning the ingredient. Of those, half (just over 2,000) should have been flagged as a concern due to association with potential harm such as potential correlation with a particular disease, in this case, as we’ll see below: breast cancer.
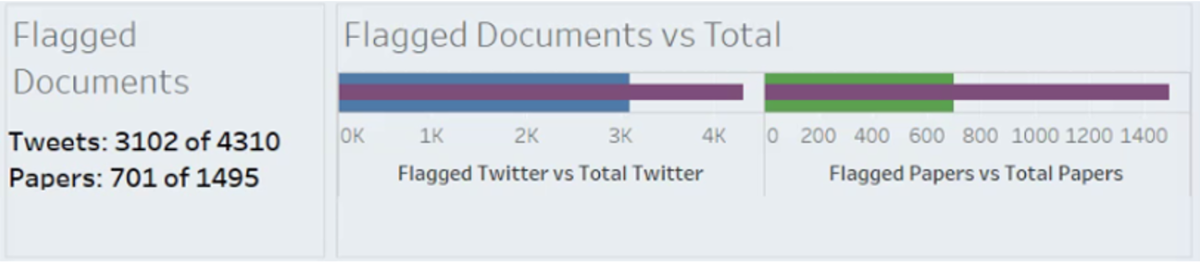
Another example is Sodium Nitrate. From 2010 to 2021, there were just under 6,000 documents mentioning the ingredient, with 3,800 of them that should have been flagged with a warning meaning that there could be concerns tied to health issues.
For certain, other factors are also at play when determining relevance of a document, such as credibility of the publication, its author, if the study was in vitro or in vivo, animal or human studies, etc., but this is all first dependent upon identifying effects in relation to an ingredient.
Another challenge for manufacturers is missing key documents by having siloed teams monitoring these documents. When data is siloed, it results in duplication of effort, leading to inefficient processes and increased operational costs. To secure a holistic view of an ingredient there are distinct sources to process, across a wide range of inputs. Even as many forward-thinking companies recognize the importance of monitoring social networks for brand health and perception, forums and blogs such as Reddit, news sources and regulatory, along with academic and scientific publications, few if any are able to synthesize these sources. For meaningful action, it’s crucial that all sources are understood collectively.
The first-mentioned example of Methyl Paraben is a good illustration of this. Even if we simplify the types of data inputs examined, and look at just Twitter and Scientific Publications, we see 3311 total documents and 2037 flagged documents. The first flagged Twitter mentions of Methyl Paraben (meaning they should raise a flag of concern that consumers are noting any potential harm) was in 2010. But publications had already – 8 years prior in 2002 – begun to raise concerns about the potential harm.
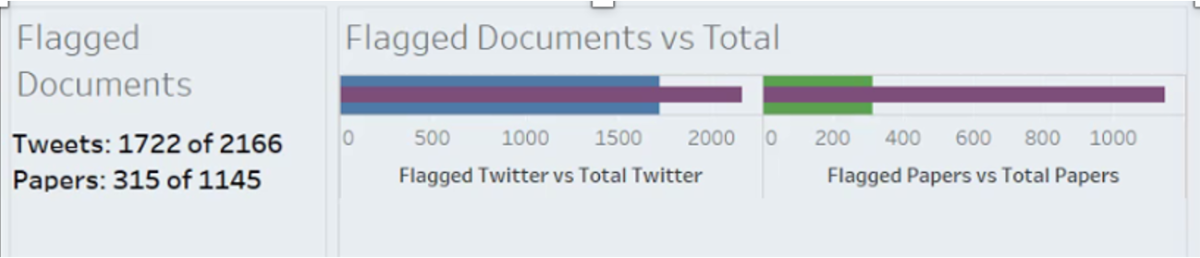
The same story unfolds for Sodium Nitrate, which saw its first flagged Twitter documents in 2014 but had flagged publications six years prior.
The ability to not simply monitor but integrate this data is critical for manufacturers who want the most complete view of their categories. It’s key to have tools in place that detect and alert about potential concerns years prior to regulatory action, which allows for companies to look for safer options, source these new ingredients, reformulate, etc.
Detection alone isn’t enough. Manufacturers must analyze the interaction of these documents globally with an eye toward patterns in the data that have probability of repeating themselves in the future. The patterns follow a similar route: from a spark of concern in the data that ultimately spreads – to other academic sources, news media, consumers and regulators.
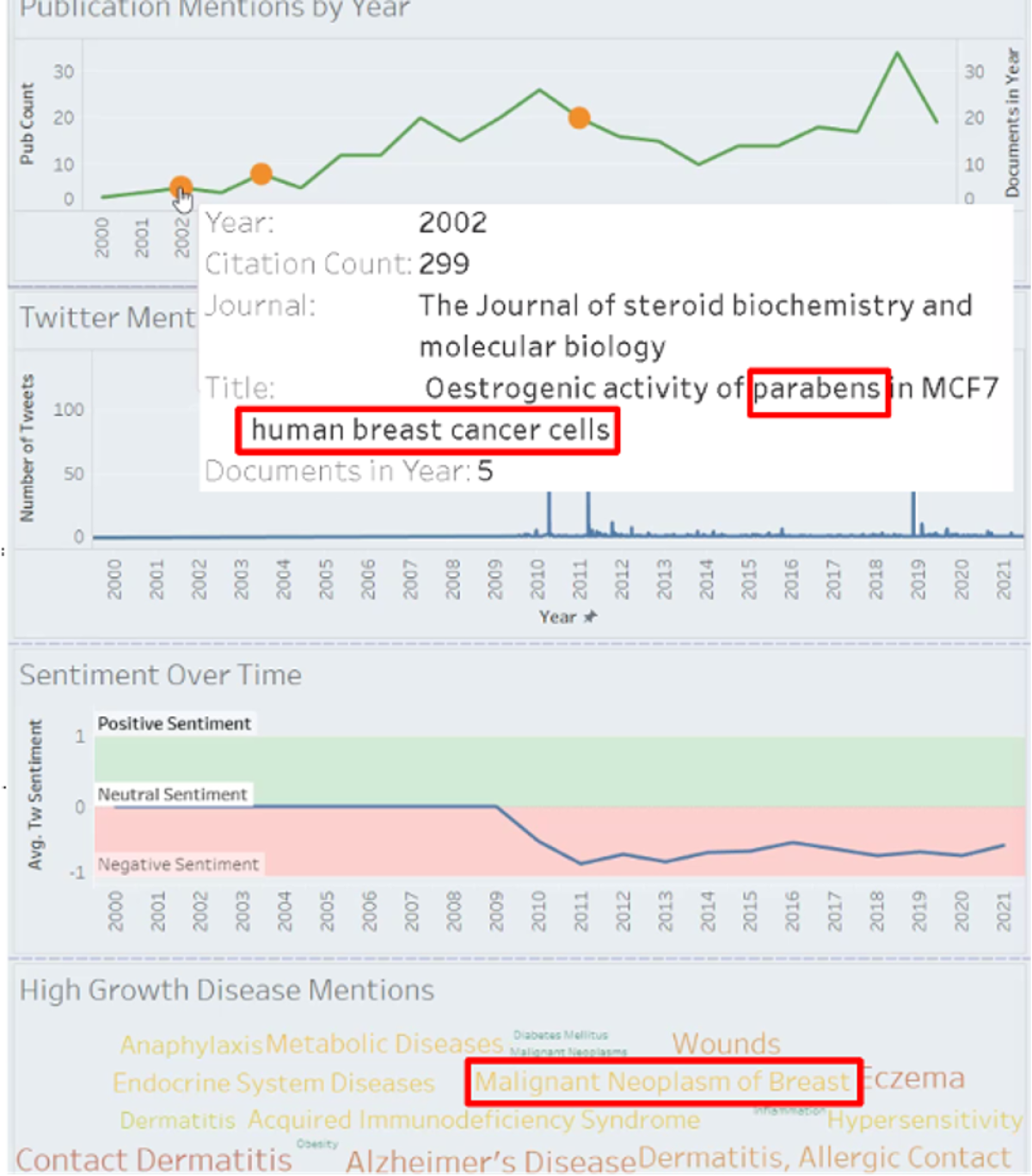
Methyl Paraben again provides an example of this. The first flagged publication about Methyl Paraben’s title reads: “Osetrogenic Activity of Parabens in MCF7 Human Breast Cancer Cells”. From its first mention on Twitter, the sentiment for Methyl Paraben has remained consistently negative, and it is often mentioned (in social, in publications) in connection with diseases, including malignant neoplasm of Breast, i.e. breast cancer.
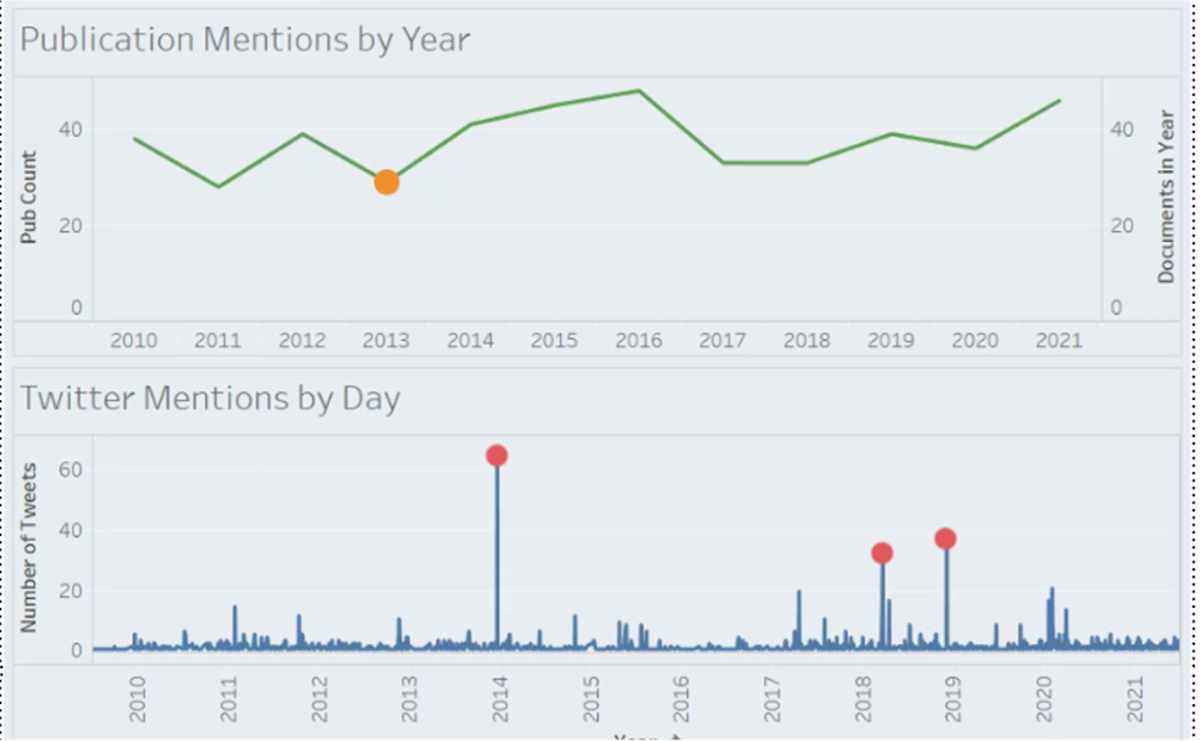
Sodium Titrate follows a similar, if more dramatic route, with a “spark” created in 2013 from an academic presentation that then is cited by more scientific studies, and is picked up in mainstream news before a spike in Twitter mentions of the ingredient rapidly following, i.e. the spread of information on social networks from the spark of scientific literature raising concerns about the ingredient.
Uncovering patterns such as these not only allows manufacturers to gain insight into what is happening right now in categories, but would also allow them – through machine learning and pattern recognition – to predict what ingredients may be a concern in the future. At 4Sight Advantage, we leverage a capability designed for the Department of Defense for some of its most strategic decisions. By applying that capability to this commercial challenge, it allows manufacturer’s space and time to reformulate and source new ingredients with an eye toward competitive advantage, not only saving their bottom lines but doing the right thing by their consumers and the environment.
